Product
GoldenRay Cloud Native Platform: Cluster Engine
Empowering Enterprise AI with Intelligent Orchestration and GPU Optimization
AI Workload Scheduler
GPU Fractioning
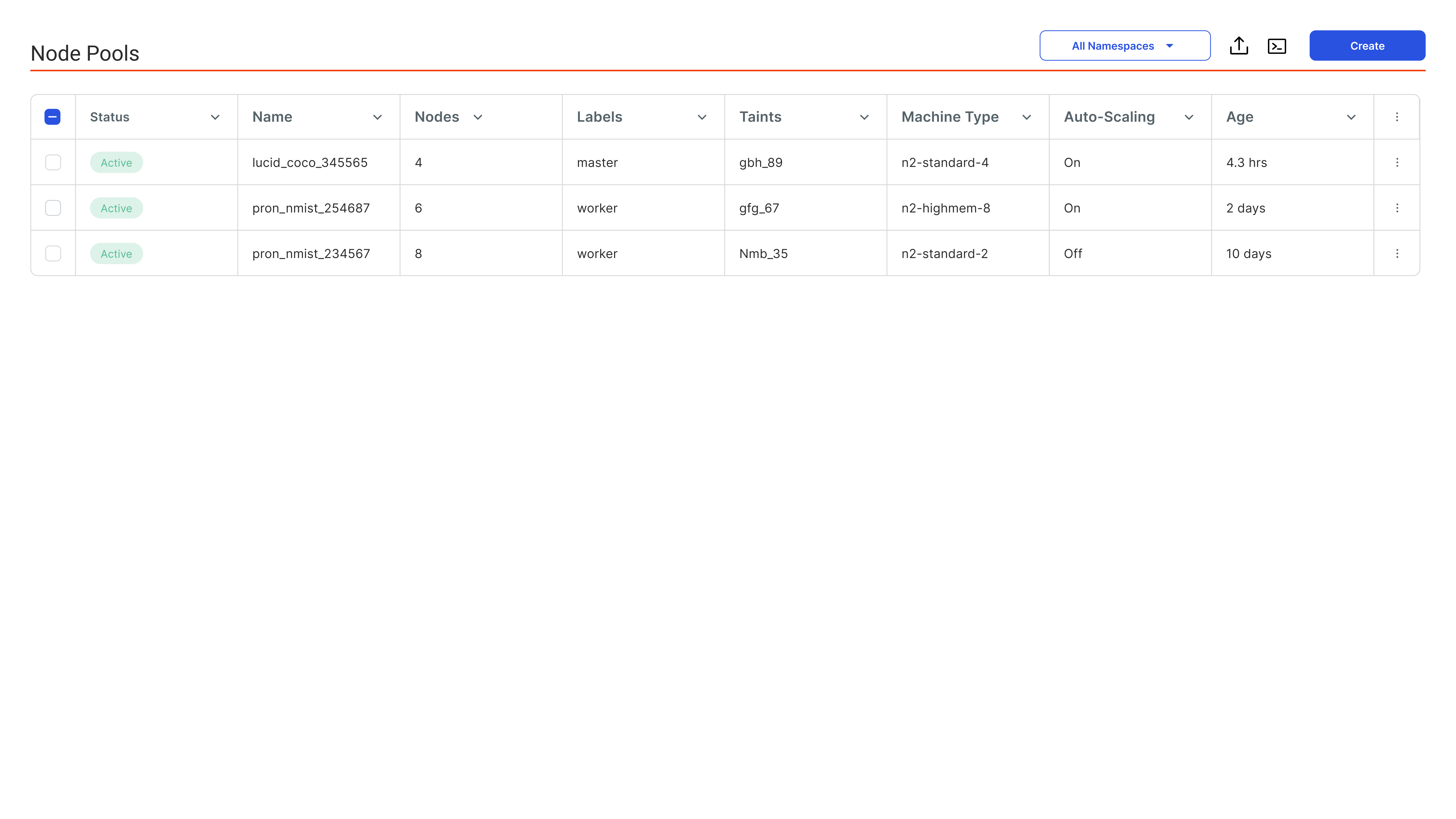
Node Pool
GoldenRay Cloud Native Platform: Cluster Engine
Intelligent Resource Management
with AI Workload Scheduler
with AI Workload Scheduler
Define user or project-level priorities and GPU quotas. GoldenRay's native scheduler dynamically
reallocates resources in real-time to ensure optimal utilization, fairness, and workload performance.
reallocates resources in real-time to ensure optimal utilization, fairness, and workload performance.
Adaptive Priority & Quota Management
Dynamically enforce GPU quotas and priorities with fair-share scheduling.
Smart Job Queuing & Batch Scheduling
Improve GPU usage with smart job queuing and priority-based batching.
Guaranteed GPU Access
Ensure reliable GPU access for high-priority workloads through dedicated quotas and isolation from shared resources.
Intelligent Bin Packing & Consolidation
Optimize GPU usage by consolidating jobs and reducing fragmentation.
Coordinated Gang Scheduling
Launch distributed jobs simultaneously with low latency across nodes.
Unified Observability Across Environments
Get full-stack insights across cloud, on-prem, and hybrid environments.
Optimize Costs with GPU Fractioning
Achieve maximum hardware efficiency and cost savings by
leveraging fractional GPU sharing for AI and ML workloads.
leveraging fractional GPU sharing for AI and ML workloads.
SHARED GPUs
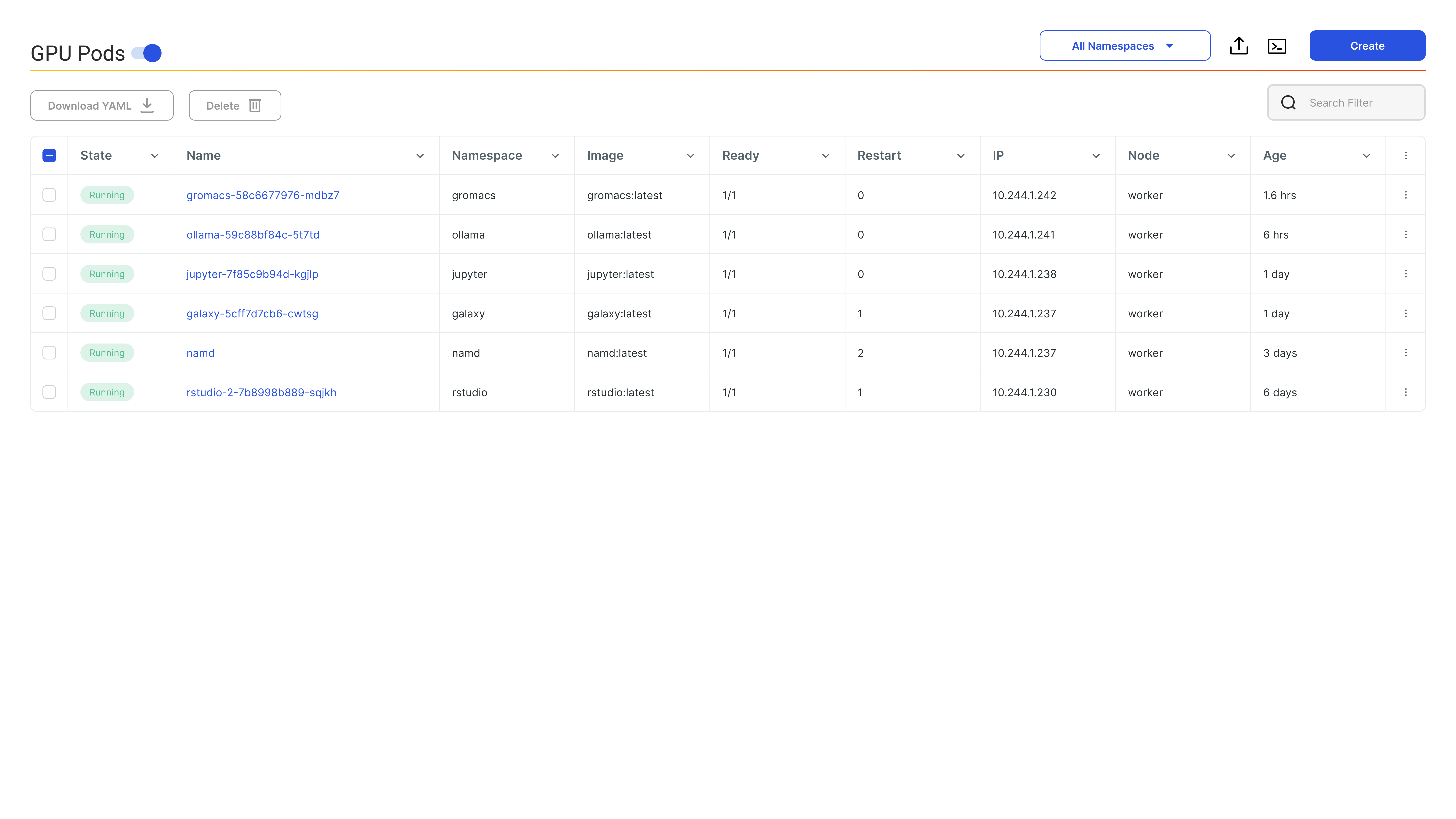
GPU Sharing for High Density Workloads
Host multiple workloads - including Jupyter Notebooks, inference endpoints, and lightweight model training, on a single GPU.
Memory Partitioning
Memory Isolation for Safe Multi-Tenant Execution
Protect workloads from memory collisions and ensure predictable performance through hardware-level and software-enforced isolation mechanisms.
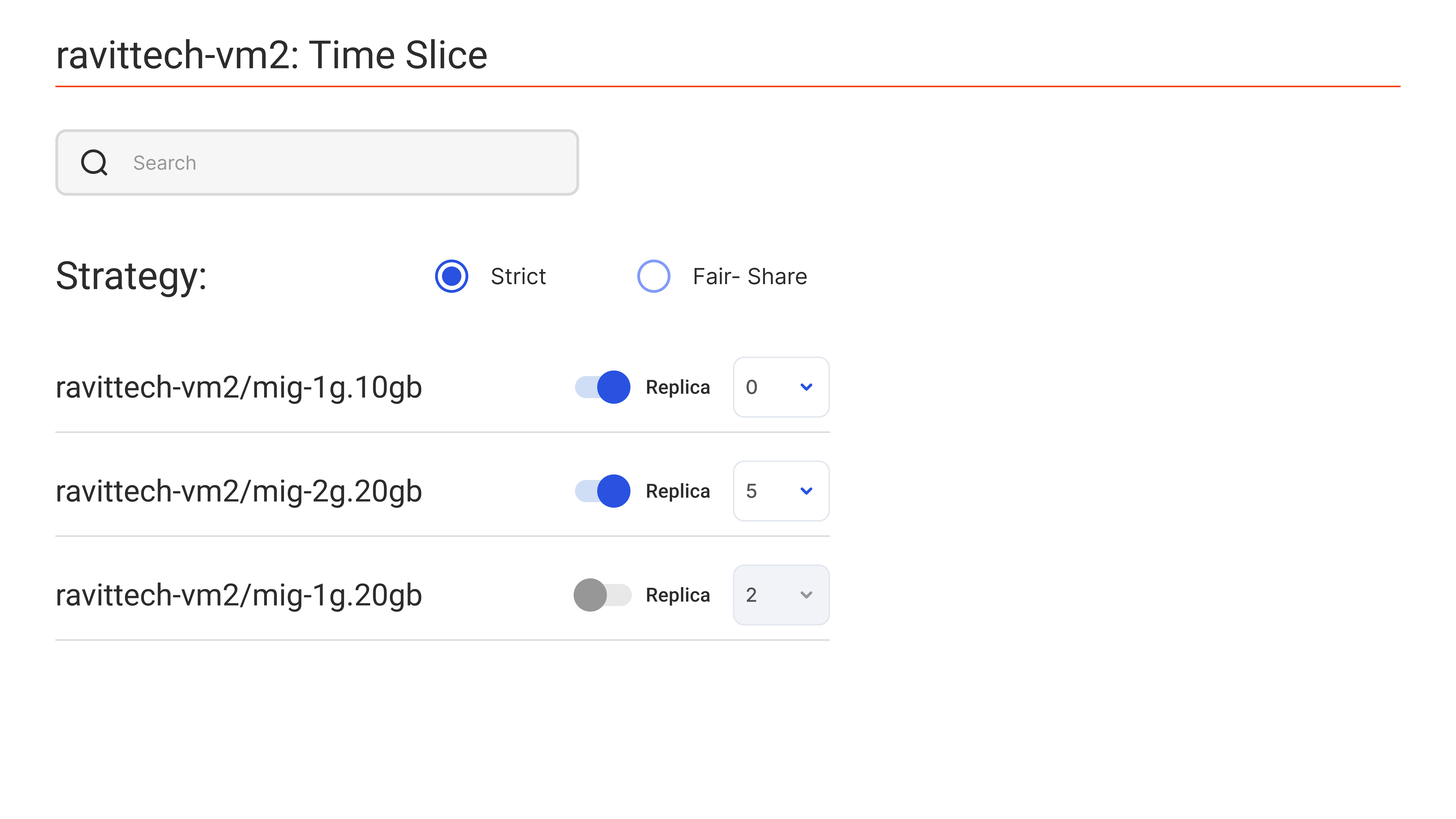
Time Slicing
Advanced Compute Time Slicing
Dynamically control compute-time allocation across multiple workloads
using precision scheduling algorithms.
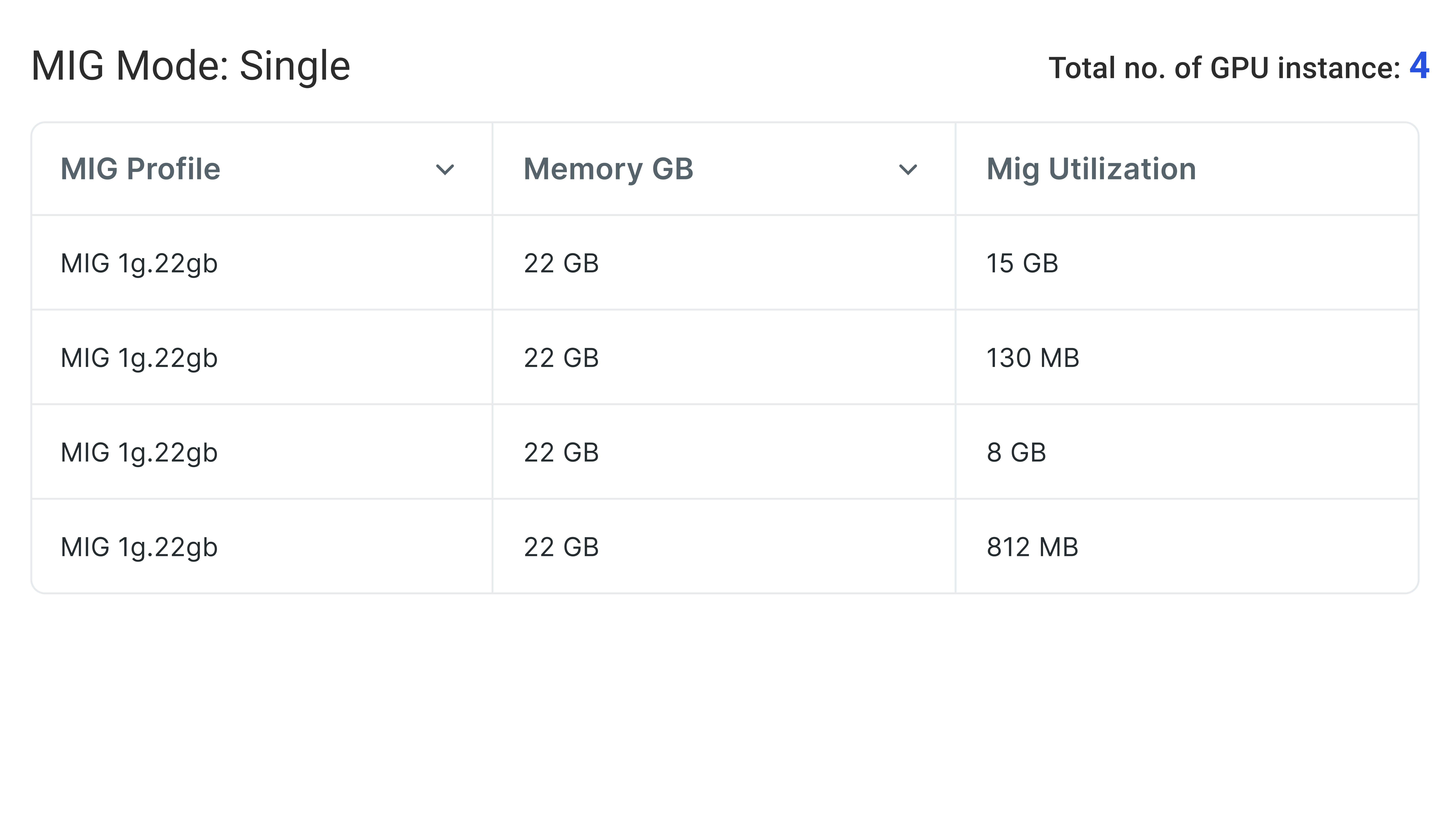
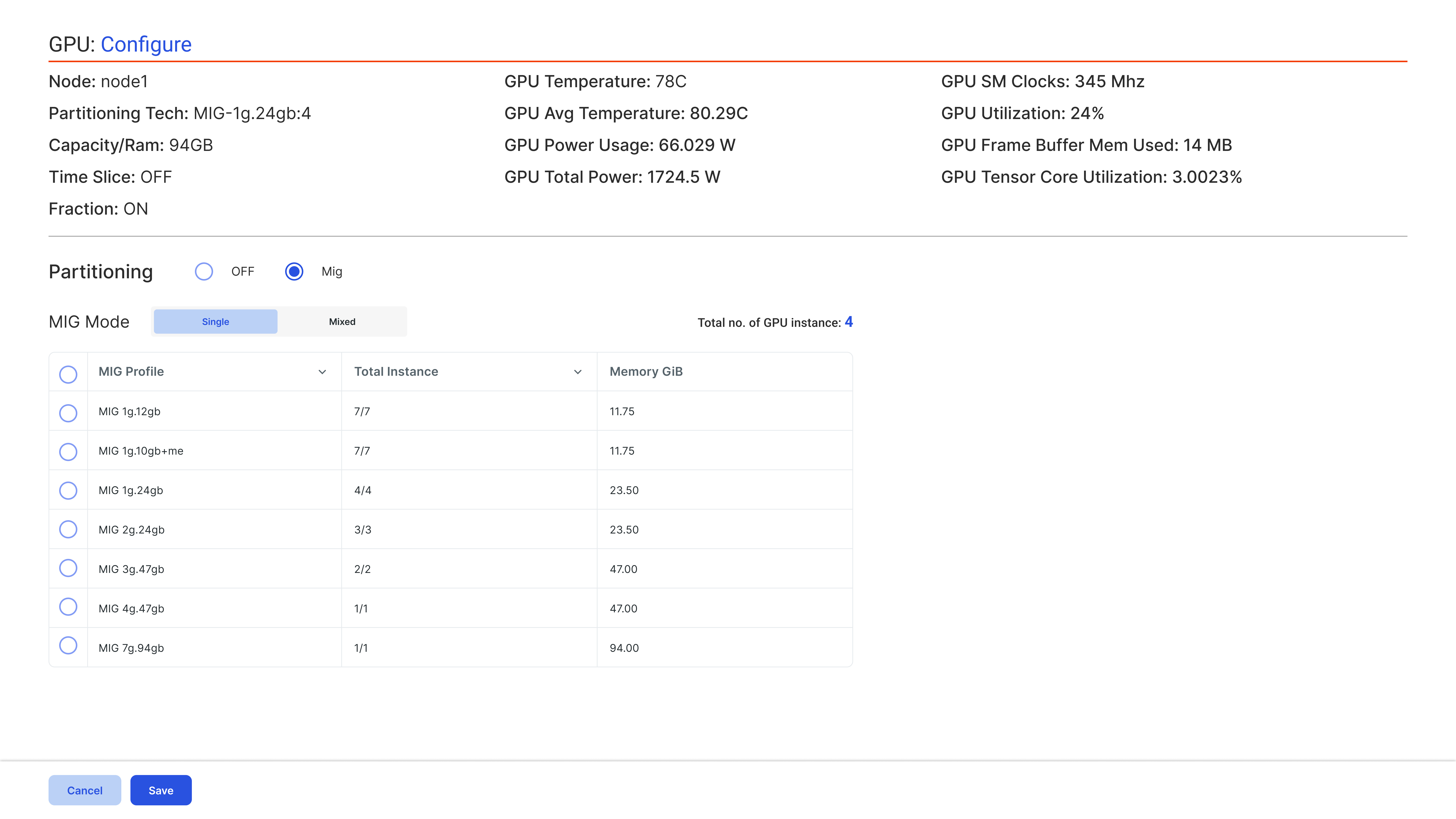
Dynamic MIG
MIG Provisioning (Multi-Instance GPU)
Provision MIG slices dynamically—without cluster downtime, node reboots, or interrupting active workloads.
Control Behavior at the
Node Pool Level
Node Pool Level
NODE POOLS
Node Pool-Level Governance
Customize GPU policies, quotas, and priorities per node pool to support diverse GPUs and enforce strict isolation, compliance, and resource governance.