Product
GoldenRay Cloud Native Platform: AI Development Reimagined
Accelerate AI innovation with an end-to-end platform that supports the entire machine learning lifecycle, from ideation to deployment.
Workspace
Training & Fine-tuning
Inference
AI Dev Tools
Tools
Workspace
Fine-Tuning and Inference
Open Source Framework
LLMs
LoRA / QLoRA
Custom
Models
Models
SLMs
Vector DB
Launch Instantly
with Pre-Built
AI Workspaces
with Pre-Built
AI Workspaces
Accelerate AI development by instantly launching fully pre-configured
environments that include your tools, libraries, and datasets-all in one place.
environments that include your tools, libraries, and datasets-all in one place.
One-Click Access to Your IDE
Connect with a single click, directly from the platform to the development environment of your choice, whether it's Jupyter Notebook, PyCharm, or Visual Studio Code.
Integrated Experiment Tracking
Track, version, and reproduce your machine learning experiments with ease. Built-in support for experiment logging and lifecycle management, keeping your workflows organized, auditable, and collaborative.
Bring Any Data, Anywhere
Connect with a single click, directly from the platform to the development environment of your choice, whether it's Jupyter Notebook, PyCharm, or Visual Studio Code.
Private LLMs/ Vault LLM/ Shielded LLModels
Pre-Integrated, Ready-to-Deploy LLM Models
Choose from a wide range of open-source and fine-tuned models tailored for diverse performance, accuracy, and use case requirements. Each model is containerized and ready for instant deployment within your private infrastructure.
Enterprise-Grade LLM Deployment Across Any Infrastructure
Performance-Driven LLM Orchestration with Deep Observability
workspace templates
Save Time and Effort with Ready-To-Use Templates
Configured templates optimized for AI and ML workloads — complete with essential tools, frameworks, and environment variables. Customize as needed or define your own setup. Our intelligent scheduling ensures optimal GPU and CPU usage, enabling you to run significantly more workloads on the same infrastructure — without slowdowns or resource conflicts.
Resource-Efficient Execution
Fully Customizable Environments
Seamless GPU/CPU Scheduling
Integrated Data Sources
Scalable Infrastructure on Demand
Collaborative Environment
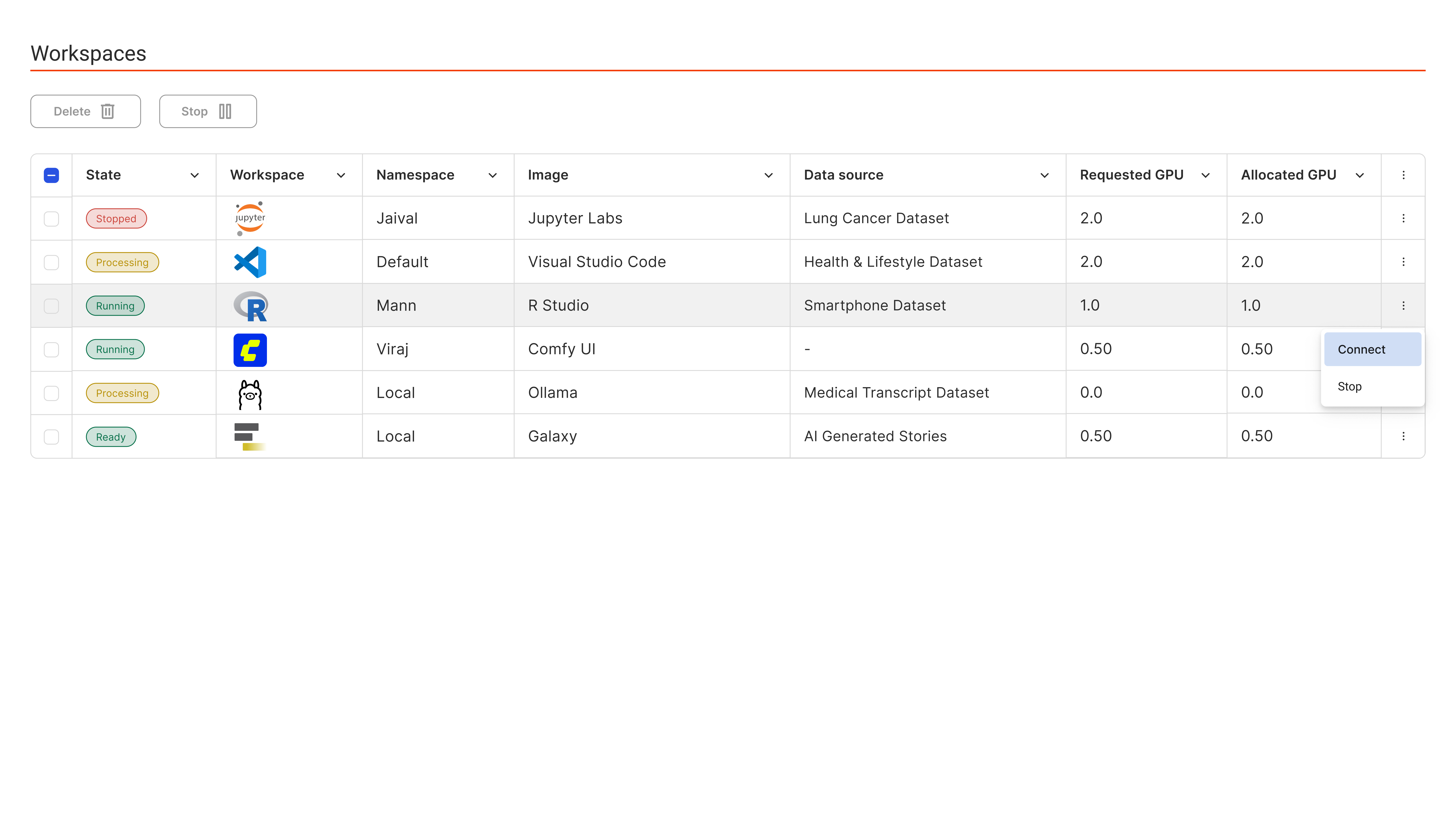
Workspaces on Demand
Instant Access. Maximum Efficiency. Built for AI.
Empower your data scientists and ML engineers with on-demand, containerized Jupyter notebooks — fully isolated, GPU-accelerated, and policy-controlled.
Launch in Seconds
Secure & Isolated
Persistent & Reproducible
Scale Up Model
Training & Fine-Tuning
Training & Fine-Tuning
Dynamically manage AI/ML workloads with intelligent scaling mechanisms and automatically adjust compute resources in real-time.
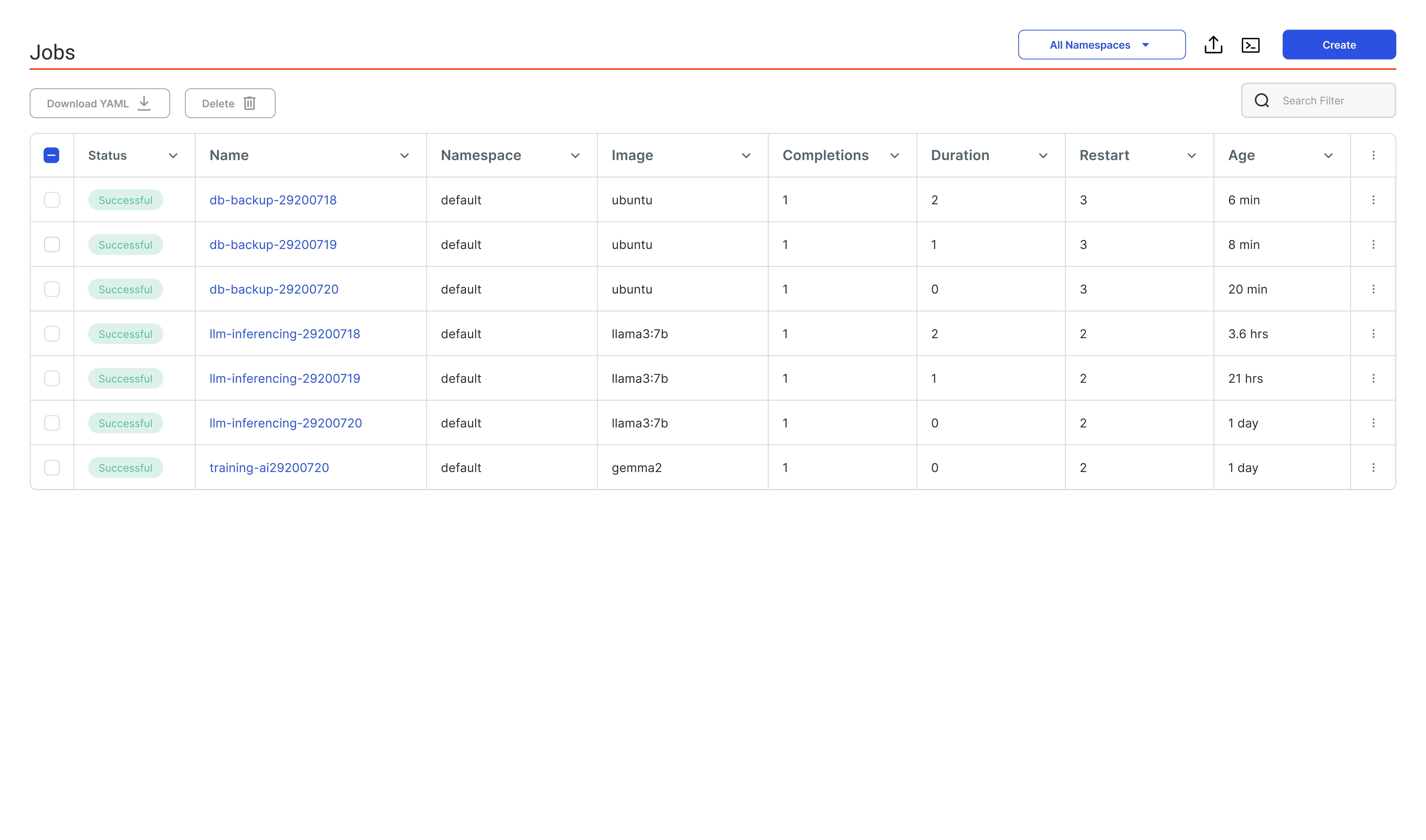
Scheduled Jobs
Flexible Job Execution
Run scheduled, recurring, or on-demand jobs effortlessly, optimized for AI/ML workloads. From scheduled model training to data preprocessing and inference tasks, jobs can be executed and managed seamlessly, ensuring consistent output without manual intervention.
Single-run training jobs
Automatic Cleanup
Robust Retry & Timeout Policies
Batch & Parallel Execution
Intelligent Auto-Scaling
Seamlessly train large models across multiple nodes and GPUs with a single command
Automatically scale compute resources in real time, optimizing performance and cost for AI pipelines. No need to over-provision. Your infrastructure scales based on live workload demands, enabling efficient use of GPU/CPU for model training, fine-tuning, and inference.
Load-Based Scaling
Efficient Resource Use
Auto-Response to Traffic Spikes
No Manual Intervention
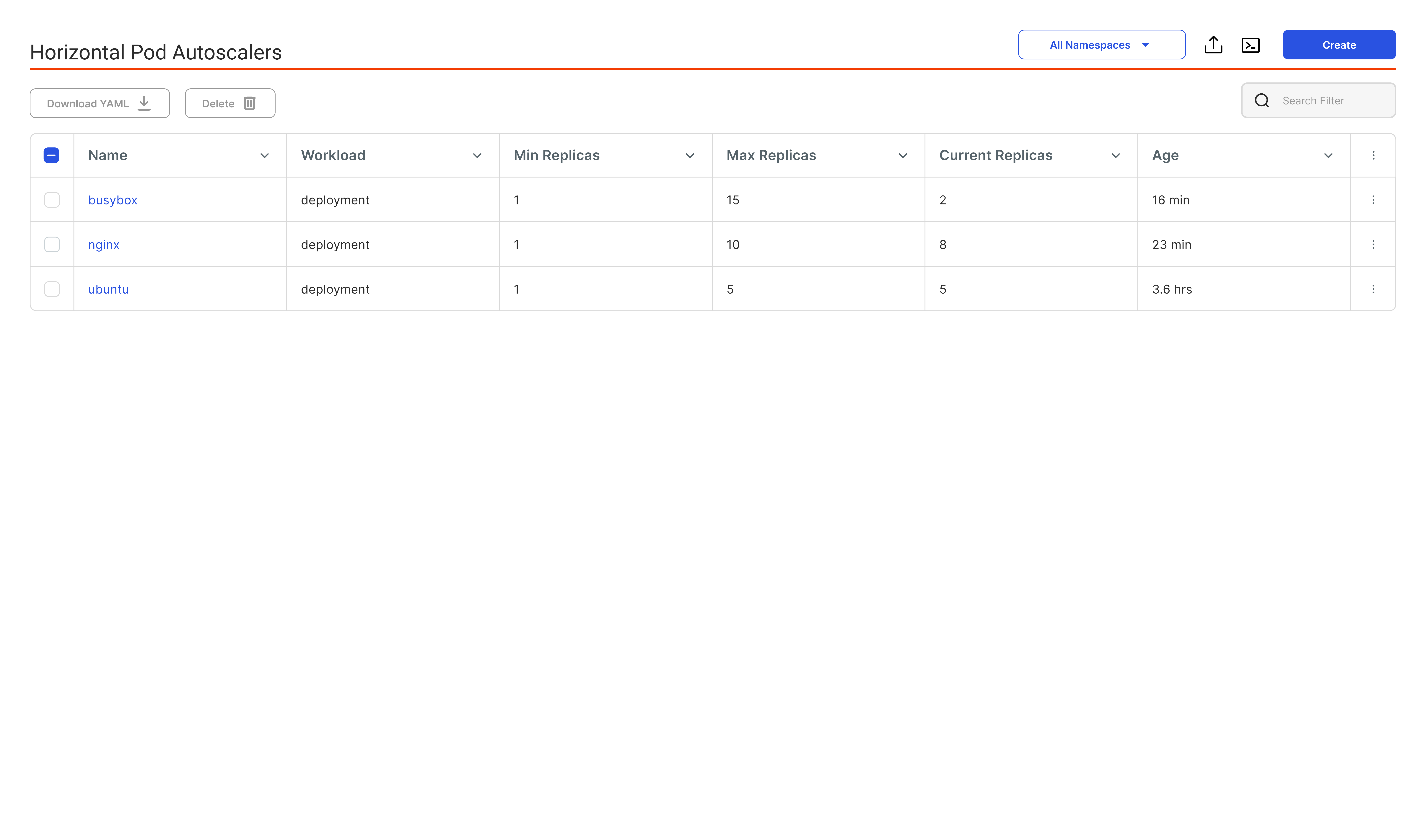
Cost-efficient and
optimized Inference
optimized Inference
Run inference workloads with optimal efficiency through smart resource use, reduced idle time,
and streamlined performance, ensuring fast, scalable, and cost-effective AI deployments.
and streamlined performance, ensuring fast, scalable, and cost-effective AI deployments.

Unified Deployment Tools
Seamlessly deploy, manage, and monitor all your models from a single control center. Gain full control over the entire lifecycle of your AI models—from versioning to deployment and real-time monitoring.

Built-In Model Catalog
Instant access to ready-to-use, enterprise-grade LLMs on your own infrastructure. Accelerate development using a curated library of pre-optimized large language models (LLMs) that can be deployed with zero external dependencies.

Intelligent Auto-Scaling (Scale to Zero)
Dynamically provision compute only when needed—automatically scale down idle models. Reduce cloud and hardware expenses by auto-scaling inactive models to zero.

Fractional GPU Allocation
Run multiple inference models on a single GPU—maximize density, minimize cost. Split GPUs into isolated slices and host several inference workloads simultaneously without performance degradation.